Ce matin en accédant à l’intranet1. Ce qui l’est plus c’est qu’aucune vérification du lien reçu n’est effectué : il m’a été possible de faire afficher un site internet extérieur.
Il m’est alors venu de faire afficher une page d’authentification pirate, me permettant ainsi de récupérer nom d’utilisateurs et mots de passe…
Le navigateur par défaut pour accéder à l’intranet étant Internet Explorer2, j’ai donc passé la matinée à fabriquer une réplique de la fenêtre de connexion Windows.
Il faut jouer sur la naïveté de l’utilisateur : pour certaines applications, l’authentification utilisateur de l’AD de sa machine Windows ne suffit pas pour se connecter. Normalement, une nouvelle fenêtre d’identification ne devrait pas trop le surprendre.
Le fait d’imiter la fenêtre de connexion ne suffit pas : il faut amener l’utilisateur à se rendre sur l’intranet sur une URL particulière, et le mieux, qu’il ne se rende pas compte que ses identifiants ont été dérobés. Une faille en cours de résolution sur le réseau interne est que le serveur d’envoi des mails ne vérifie pas vraiment l’identité. Il est donc possible d’envoyer un mail à plusieurs personnes en se faisant passer pour un autre. Il ne reste plus qu’à susciter l’intérêt de l’agent pour qu’il clique sur le lien : un message concernant une intervention du maire, un fiche de recommandation sur je ne sais quel sujet, …
Pour mettre en place cette récupération d’identifiants, je souhaitais que l’URL incluse ressemble à quelque chose d’officiel. J’ai opté pour auth.ville.local, sachant que le suffixe DNS des connexions filaires est ville.local. De plus, il est existe réellement un serveur auth.ville.fr, mais seulement accessible depuis l’extérieur. La ressemblance est relativement bonne, surtout pour un utilisateur naïf !
J’ai donc mis en place une machine virtuelle sous Ubuntu serveur, en y configurant un serveur Web, ainsi que son nom « auth », qui une fois sur le réseau, est devenue auth.ville.local. Parfait
Cette démarche a mis en évidence un autre problème du réseau interne : toute machine se connectant en filaire sur le réseau à l’intérieur de la DSIT3 obtient le suffixe DNS « ville.local ». Donc toute personne ayant renommée intelligemment sa machine peut tenter « d’usurper » l’identité d’une autre machine. C’est ce que P. a fait : il a nommé sa machine sous Linux du même nom que celle de A., et oh magie, lorsque je tentais un ping vers le nom de machine de A., c’est en fait la machine de P. qui répondait.
P. aurait souhaité prendre le nom d’un serveur, pour voir comment le réseau réagirait, mais cela ne lui a pas été possible4.
Le problème a été remonté mais n’est pour l’instant pas une priorité absolue. Il s’agit du réseau interne, et n’importe qui ne peut pas entré ni tombé sur une prise Ethernet active. L’extérieur de réseau est lui mieux sécurisé, et c’est là dessus que l’on souhaite se concentrer pour l’instant.
-
Site web de la collectivité, accessible uniquement en interne, présentant les services internes, l’annuaire, etc), je me suis aperçu en affichant le webmail que l’intranet incluait directement la page grâce à une URL fournie en paramètre. Le webail étant hébergé en local rien de très choquant ((Même si la technologie utilisée est obsolète : le iFrame :( ↩
-
Oui je sais… ↩
-
Il faut déjà réussir à le faier, le bâtiment régulant toutes les entrées. ↩
-
Et on comprend bien, il aurait fallu un réseau test à côté pour le faire. ↩

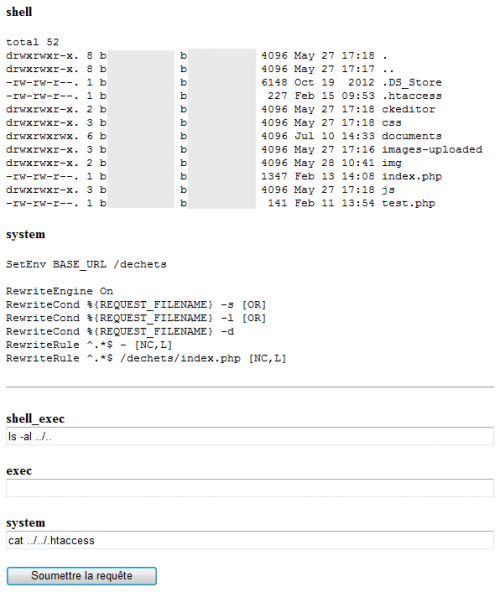 L’après-midi a été consacré à la recherche des lignes problématiques dans le code source que B. a pu nous fournir. Les développeurs ont utilisés le framework Zend pour leur application. Le problème, c’est que Zend n’échappe les caractères par défaut lors de réception de données
L’après-midi a été consacré à la recherche des lignes problématiques dans le code source que B. a pu nous fournir. Les développeurs ont utilisés le framework Zend pour leur application. Le problème, c’est que Zend n’échappe les caractères par défaut lors de réception de données